“Dew knot trussed yore spell chequer two fined awl yore mistakes.” – Brendan Hills
Although data modeling has been around for over 30 years, it ranks among the top areas from whence database application problems arise. Moreover, the severity of the problems ranges from totally incorrect functionality to freakishly miserable performance. How can such an established technique yield such terrible results? The answer is quite unnerving.
Today’s data modeling tools are amazingly good. Unfortunately, the same is quite often not true about the people using them. This may sound harsh at first, but would you let a person draw the blueprints for your new home if all they had was one semester of formal architectural training? How about if they had no training, but had been a contractor who built homes for the past five years? What if they had attended a three-day architecture class and had used that training on occasion? Nervous yet? It’s only your home.
The point is that even though data modeling has been around for some time and is now being used extensively, many practitioners have had limited training or mentoring in the formal techniques. Think this is an unfair assessment? Then the next time a data modeler hands you a supposedly third normal form ERD, simply ask them to define first, second and third normal form or why that’s important to your business requirements. Still not convinced? Then why aren’t we all great novelists? We all speak the language and have Microsoft Word on our PCs. Beginning to see the analogy?
Just remember that using data modeling tools does not automatically guarantee success. Yes, today’s ER tools support good relational design. Yes, today’s ER tools have model checking utilities. And yes, today’s ER tools generate fairly good DDL. But give me any programming language compiler and I can write an infinite loop. The same is true with data modeling. The “garbage in, garbage out” principle applies – you just end up with a pretty picture of the garbage as well. And garbage begets garbage. So the application programs cannot compensate for bad database design – in fact, they usually make a bad thing even worse.
Each issue, we’ll look at some of the more common modeling mistakes and their impacts. This month we’ll start with my favorite: primary, unique and foreign keys (just a little for now). Then in the next issue, we’ll dig even further into the complexities of foreign keys.
Implement all candidate keys
Look at the entity and its two most common table implementation options modeled in Figure 1. PERSON_LOGICAL represents what we’re told as the business requirements. Notably, that a person can be uniquely identified by either their SSN or the concatenation of their First Name, Last Name, Gender, and Birth Date. Thus PERSON_LOGICAL has two candidate keys: AK1 and AK2, respectively.
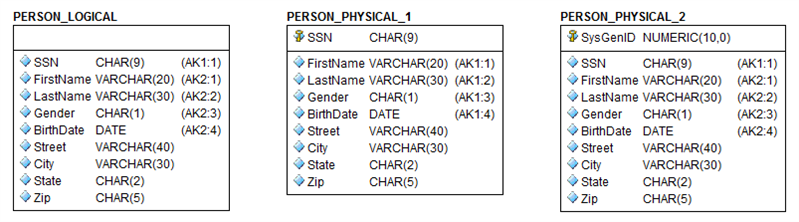
Figure 1
PERSON_PHYSICAL_1 represents the simple choice of merely choosing the shortest candidate key as the primary key, with all the remaining candidate keys implemented as alternate unique keys. On the other hand, PERSON_PHYSICAL_2 represents adding a meaningless, system-generated surrogate key as the primary key, with all candidate keys still implemented as an alternate unique key. This second method is often chosen to keep SQL join coding simple and performant.
The problem with either approach is that many modelers or DBAs will choose not to implement the remaining candidate keys in order to minimize the number of indexes, thereby saving space and the performance overhead for inserts, updates and deletes to keep those indexes current. But this tradeoff also negates the business requirements!
PERSON_PHYSICAL_1 without the AK permits people with duplicate concatenations of First Name, Last Name, Gender, and Birth Date. While PERSON_PHYSICAL_2 without either AK1 and AK2 is even worse as it also permits people with duplicate SSNs. Less space and faster performance are truly moot points if the data is incorrect! Rule #1: Always implement all candidate keys in order to maintain business requirements.
Foreign keys can also be candidate keys
In effect, this is a restatement of the above that stresses that being a foreign key does not negate the ability to be either a primary or alternate key. It may seem superfluous to state this, but I’ve seen this problem more than most. Let’s look at the concept of marriage as shown in Figure 2.
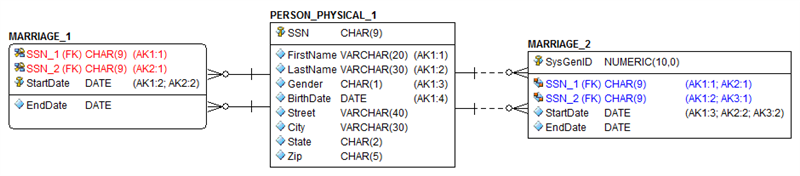
Figure 2
MARRIAGE_1 demonstrates a primary key formed from two identifying relationships from PERSON_PHYSICAL_1 plus the marriage start date. But note the two additional alternate keys. What’s up with that? Well, the business rule might be that a particular person can only get married once per day. So SSN_1 and SSN_2 are parts of the primary, unique, and foreign keys – and this is legal. Note that many ER tools will generate suboptimal index DDL for this construct (i.e. five indexes) not realizing that if the FK columns are defined as the leading portion of the AK indexes then you don’t need to create separate indexes that overlap.
MARRIAGE_2 is an attempt to correct this index design flaw in the model by adding a meaningless surrogate key as the primary key, with each candidate key implemented as an alternate key. This too will also cause most ER tools to generate suboptimal index DDL with five indexes rather than three by not eliminating the extra FK indexes which overlap the AKs.
As before, the problem is that many modelers or DBA’s will choose not to implement the candidate keys to minimize the number of indexes thereby saving space and minimizing overhead for inserts, updates, and deletes. Once again this tradeoff negates the business requirements! As before, always implement all candidate keys.
Separate the concept of keys from indexes
In both the above issues, the real culprit is peoples’ inability to differentiate keys from indexes. Keys enforce business rules – it’s a logical concept. Indexes speed up database access – it’s purely a physical concept. Yes, primary and unique keys require indexes in order to affect the uniqueness, but foreign keys do not require indexes – though DBA’s very often index them for performance and locking reasons.
Let’s go back to Figure 2. Assume we model it as shown in MARRIAGE_2 and pass it on to a DBA who’s quite comfortable with both data modeling and index design. We can implement merely two indexes in just 41 bytes that support all the defined keys – saving 34 bytes or 45%. Thus we get correct business rules, fast access, and minimum space.
Index 1 would be SSN_1 + Start Date + SSN_2. Index 2 would be SSN_2 + Start Date. By using the DBA’s knowledge of the databases leading column index capabilities, we can keep separate the concept of five keys over nine columns and the two indexes over five columns that support their needs.
Likewise, that DBA could also optimize MARRIAGE_2 to use merely three indexes in just 34 bytes – saving 41 bytes or 55%. Clearly, keys do no equal indexes.
RULE #2: Implement the least number of indexes which can effectively support all the keys.
Keys do one job and business rules do all the others
Look again back at Figure 2. Let’s assume we’re using MARRIAGE_1 as our solution. Can the primary key of SSN_1, SSN_2, and Start Date really sufficiently differentiate one marriage from another? For the sake of argument, let’s say yes. But does this primary key guarantee valid or legal instances? The answer is a resounding “no”. It is entirely possible to have genuinely unique but still illegal instances of data if all you have are the keys.
Let’s assume our business analyst tells us that, for this application, the following marriage rules are true (note: these rules are for demonstration purpose only, and do not reflect any kind of commentary or point of view regarding the concept of marriage).
- Those people must not be the same person
- Both people must be at least 18 years of age
- Both people must not already be actively married
- At least one person must have a complete address
So where’s that displayed in our model? The answer is nowhere. These requirements are known as business rules and should be documented in modeling tools so as to generate either constraints or triggers in the database. If not, then all your application developers must instinctively know all these rules and consistently program them throughout the entire application. Yeah, right – then I’ve got some great swampland to sell you too.
In Figure 3 below, we have a screen snapshot showing how to define business rules at the entity/table and attribute/column levels in ER/Studio – Idera’s world-class data modeling tool. ER/Studio has complete trigger editing and template facilities as well. The DDL following Figure 3 was generated from ER/Studio and meets all of the above business rules.
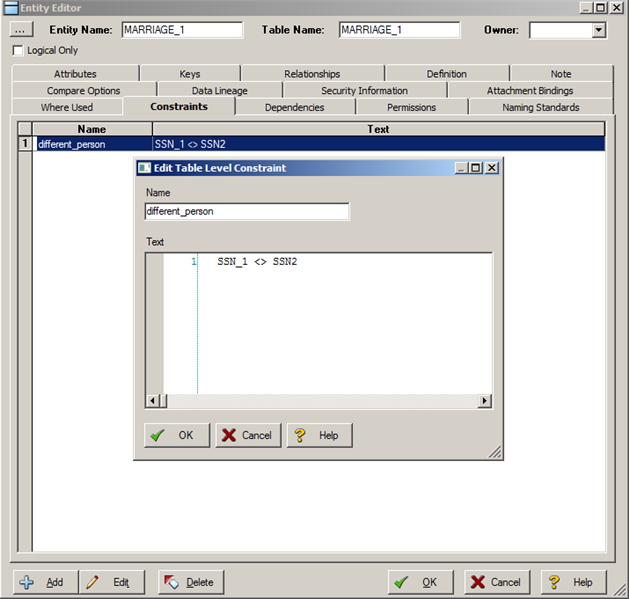
Figure 3
CREATE TABLE MARRIAGE_1(
SSN_1 CHAR(9) NOT NULL,
SSN_2 CHAR(9) NOT NULL,
BeginDate DATE NOT NULL,
EndDate DATE NOT NULL,
CONSTRAINT different_person CHECK (SSN_1 <> SSN2)
CREATE UNIQUE INDEX PK7 ON MARRIAGE_1(SSN_1, SSN_2, BeginDate);
CREATE UNIQUE INDEX AK2 ON MARRIAGE_1(SSN_1, BeginDate);
CREATE UNIQUE INDEX AK3 ON MARRIAGE_1(SSN_2, BeginDate);
CREATE INDEX Ref51 ON MARRIAGE_1(SSN_1);
CREATE INDEX Ref53 ON MARRIAGE_1(SSN_2);
ALTER TABLE MARRIAGE_1 ADD
CONSTRAINT PK7 PRIMARY KEY (SSN_1, SSN_2, BeginDate)
USING INDEX PK7;
ALTER TABLE MARRIAGE_1 ADD CONSTRAINT RefPERSON_PHYSICAL_112
FOREIGN KEY (SSN_1)
REFERENCES PERSON_PHYSICAL_1(SSN);
ALTER TABLE MARRIAGE_1 ADD CONSTRAINT RefPERSON_PHYSICAL_132
FOREIGN KEY (SSN_2)
REFERENCES PERSON_PHYSICAL_1(SSN);
create trigger CHECK_PEOPLE
before insert
on MARRIAGE_1
for each row
declare
— Declare User Defined Exceptions
too_young exception;
pragma exception_init(too_young,-20001);
is_married exception;
pragma exception_init(is_married,-20002);
no_address exception;
pragma exception_init(no_address,-20003);
v_too_young integer;
v_is_married integer;
v_no_address integer;
begin
— See if either person is under 18 years old
select count(*)
into v_too_young
from person_2
where ssn in (:new.ssn_1, :new.ssn_2)
and birthdate < sysdate-(365*18);
if (v_too_young > 0) then
raise too_young;
end if;
— See if either person is currently married
select count(*)
into v_is_married
from marriage_1
where (ssn_1 in (:new.ssn_1, :new.ssn_2)
or
ssn_2 in (:new.ssn_1, :new.ssn_2))
and (enddate is null
or
enddate > sysdate);
if (v_is_married > 0) then
raise is_married;
end if;
— Verify that at least one address is known
select count(*)
into v_no_address
from person_2
where ssn in (:new.ssn_1, :new.ssn_2)
and
street
is not null
and
city
is not null
and state is not null
and
zip
is not null;
if (v_no_address = 0) then
raise no_address;
end if;
exception
when too_young then
raise_application_error(-20001, ‘Illegal Marriage: both parties must be >= age 18!’);
when is_married then
raise_application_error(-20002, ‘Illegal Marriage: both parties must be single!!!’);
when no_address then
raise_application_error(-20003, ‘Illegal marriage: at least one address required!’);
end;
/