Introduction
When we talk about SQL Server indexes, we are usually discussing the rowstore clustered or non-clustered index. However, along with rowstore indexes, SQL Server has columnstore indexes as well. In today’s blog post, we will be discussing the columnstore index and columnstore storage. A columnstore index stores each column in a separate set of disk pages. This method contrasts with the traditional data storage practice of storing multiple rows per page.
What is the Columnstore Index?
SQL Server has two kinds of storage. The first one is what we are very familiar with – rowstore. The second is columnstore, and it was introduced to SQL Server a few years ago. A rowstore index stores rows of data on a page and a columnstore index keeps all data in a column on the same page.
The bottom line is that these columns are much easier to search. Instead of a query searching all data in an entire row regardless of its relevance, columnstore queries need only search a smaller number of columns. This efficiency saving means significant increases in search speed and reductions in hard drive use. Additionally, the columnstore indexes are heavily compressed, translating to even greater memory efficiency and faster searches. Now, this is only possible when the query needs to search through a single column’s data.
You can see an illustration of the difference between the columnstore and rowstore approaches below:
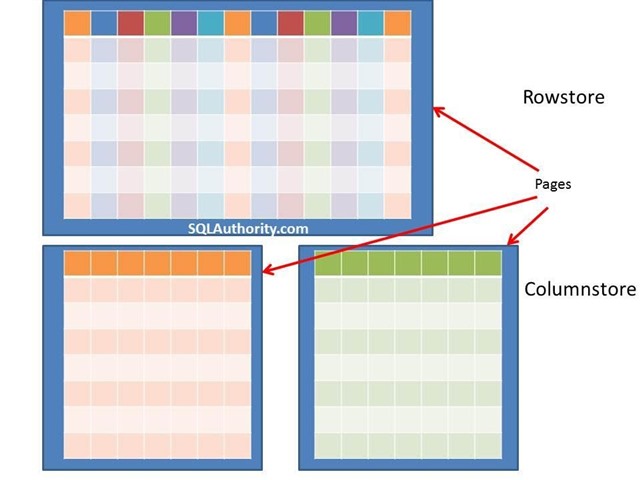
Image Courtesy of https://blog.sqlauthority.com
A columnstore index stores each column in a separate set of disk pages, rather than storing multiple rows per page as we would traditionally store data. In the rowstore indexes, multiple pages will contain multiple rows of columns spanning across multiple pages. In the case of columnstore indexes, multiple pages will contain multiple single columns. This change in data storage methodology has one significant upshot. A query now only needs to fetch from the disk the columns necessary to solve itself, rather than reading everything.
When to use the Columnstore Index?
The answer to this question is pretty straightforward. Use a columnstore index when you have aggregate operations on columns, and the data in the table is so vast that with traditional storage (rowstore) the aggregation takes a long time to compute.
Here is an example of a query which would take a long time to complete if you run it on a database with a table size in the range of hundreds of gigabytes (GB).
SELECT ProductID, SUM(UnitPrice) SumUnitPrice, AVG(UnitPrice) AvgUnitPrice,
SUM(OrderQty) SumOrderQty, AVG(OrderQty) AvgOrderQty
FROM [dbo].[MySalesOrderDetail]
GROUP BY ProductID
ORDER BY ProductID
GO
As you can see in the query above, there are a few columns which we have aggregated using aggregation functions like SUM and AVG. You can create the following columnstore index to improve the performance of the query.
CREATE NONCLUSTERED COLUMNSTORE INDEX [IX_MySalesOrderDetail_ColumnStore]
ON [MySalesOrderDetail]
(UnitPrice, OrderQty, ProductID)
GO
When you rerun the query after creating the index, you will see a drastic reduction in the IO and the time consumed by the query to complete. I have previously done this demonstration in detail, and you can read about it here.
Query to List All Columnstore Indexes
A recurring question on my blog is how to list all the columnstore indexes with the schema and table names. Here is the script which will do that for you.
SELECT OBJECT_SCHEMA_NAME(OBJECT_ID) SchemaName,
OBJECT_NAME(OBJECT_ID) TableName,
i.name AS IndexName, i.type_desc IndexType
FROM sys.indexes AS i
WHERE is_hypothetical = 0 AND i.index_id <> 0
AND i.type_desc IN ('CLUSTERED columnstore','NONCLUSTERED COLUMNSTORE')
GO
Here is the resultset of the query above when I ran it against SQL Server Sample Database WideWorldImporters. Here are the instructions on how you can install the sample database.

Summary
The columnstore index is a vast subject, and we could write many blog posts on this topic. This blog post’s goal was to give you a basic idea about how column store indexes work and where we can use them. Just like any other index, overusing columnstore indexes for your database is a bad idea. Where indexing is concerned, it is always best to use moderation.
With this, I complete this 5-part series of blog posts. We will meet again very soon in another blog series to discuss SQL Server Performance troubleshooting techniques.