It’s not uncommon to observe rampant over reliance of database application code on TEMP tables, most often as a SQL language programming crutch. I have a theory as to why. Programmers are chiefly taught record oriented or “record at a time” processing logic as for accessing data. Some lucky students might experience some exposure to a set oriented language such as LIS, but usually insufficient to adequately prepare them for SQL’s set based foundation. As such they often muddle along as best they can – which most often means liberally using TEMP tables. Now while there are legitimate cases where a TEMP table makes sense and is required, it should be the exception rather than the rule. If nothing else, it should at least be the choice of last resort after attempting to accomplish the task within a Single SQL statement.
I also believe that the way programmers think is more about “how” vs. “what”. You’ve most likely heard the theory about “right-brained” vs “left-brained. I content that “how” is more analytical and methodical thinking and thus left-brained. Therefore “what” is more creative or artistic, and therefore right-brained. While this observation is more opinion than fact, evidence seems to fit such a conclusion. For now let’s accept that premise and see how it might compound this problem of over reliance on TEMP tables.
The business person might state a problem like this, what percentage of our employees are making 20% more than their department average in our largest 10% of departments? But the programmer tends to dissect that into several smaller problems:
- What are the largest 10% of departments by employee head count
- How many employees per department for those large departments
- What is average salary per department for those large departments
- How many employees in a large department are paid 20% > average
- How many employees are there in total
- What is the percentage of those making more than average overall
There’s nothing wrong with dissecting a problem per se. Remember we all learned about the advantages of the “divide and conquer” approach to problem solving and coding. The main problem is that a “record at a time” attitude will quite often result in multiple SQL statements with intermediate results stored in TEMP tables to be passed on to the following SQL statement. You might argue “So what as the correct result is returned and that’s what matters?” However by subdividing the original problem into multiple smaller ones and thus multiple SQL statements, the database SQL query optimizer can only formulate execution plans for those smaller SQL statements rather than potentially finding a superior approach when the whole problem is presented as a single SQL statement. Moreover creating TEMP tables will consume disk space which when later dropped could end up fragmenting your storage space. Plus you may need to create indexes on your TEMP tables to duplicate what may already exist on the table, so once again it could exasperate your storage issues.
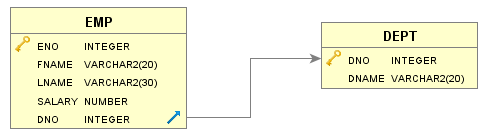
I used a simple data model with just two tables as shown here.
The single SQL statement query to obtain the answer that I came up with for SQL Server was as follows (there could of course be other answers which might be superior – so please comment your ideas):
with num_emps as (select count(eno) as xcnt from emp),
avg_dsal as (select dno, count(eno) as xcnt, avg(salary) as xavg
from emp group by dno),
dep_data as (select count(*) as xcnt
from emp join avg_dsal on emp.dno=avg_dsal.dno
where emp.salary>avg_dsal.xavg*1.2
and avg_dsal.xcnt in (select top 10 percent
count(*) as xcnt from dept))
select dep_data.xcnt, num_emps.xcnt, CONVERT(VARCHAR(50),
cast(dep_data.xcnt as decimal)/
cast(num_emps.xcnt as decimal)*100)+' %' AS [%]
from dep_data, num_emps
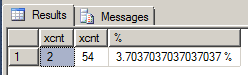
The result for my sample data which I calculated by hand to make sure was 100% correct was:
While writing a query such as this might take more time, I suggest that it’s well worth the time for all the reasons already stated. I also think from a maintainability and readability standpoint it’s also superior. I often have to ask people who create TEMP tables lots of questions when I have to work on their code.