No matter what database you’re working with, at some point performance becomes an issue which may require further investigation into possible causes. Often DBAs will first check that there are no obvious issues such as:
- Database server or VM resource bottlenecks
- Sub-optimal database parameter configuration
- Atypical database waits or wait events contention
- Unusual or overlapping and competing workloads
In fact, Brent Ozar, a highly respected SQL Server MVP and expert, has a recent blog titled “Do I Have A Query Problem Or An Index Problem?” where he proposes following his “QTIP” method once these obvious issues are eliminated. This method suggests next dissecting the probable and underlying cause, the SQL statement itself, as follows:
- Query Plan
- Text of the query
- Indexes used
- Parameters used
I fully agree with this approach. Moreover, I believe that this approach is truly database agnostic (i.e. will work equally well for any database). Here we’re going to focus on the third bullet – the indexes. Indexes are pretty much the same basic mechanism across most databases, a secondary structure that improves the speed of data retrieval operations on a database table at the cost of additional writes and storage space to maintain the index data structure. So as a “friend” they improve query speed, while as a “foe” they require extra space and writes. So the question is “What’s the ideal balance between these two opposing characteristics?” For that, we need to better appreciate these overheads.
Let’s utilize the two relatively simple tables for employee (EMP) and department (DEPT) shown here in Figure 1, a data model generated by Aqua Data Studio.
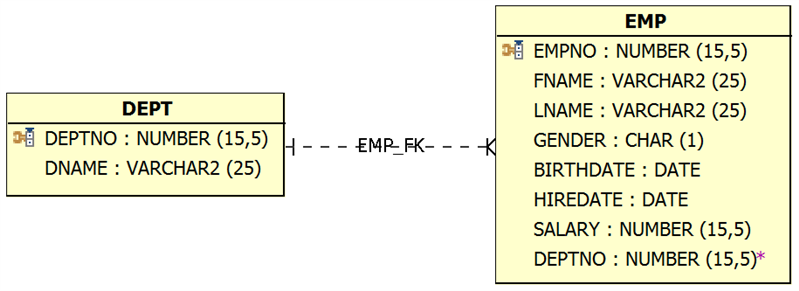
Figure 1: Simple Data Model
Here’s the basic Oracle DDL also generated by Aqua Data Studio.
/*
Script generated by Aqua Data Studio 19.0.0 on Jul-27-2018 02:57:53 AM
*/
CREATE TABLE DEPT (
DEPTNO NUMBER(15,5) NOT NULL,
DNAME VARCHAR2(25) NOT NULL
CREATE UNIQUE INDEX EMP_PK ON (EMPNO);
CREATE TABLE EMP (
EMPNO NUMBER(15,5) NOT NULL,
FNAME VARCHAR2(25) NOT NULL,
LNAME VARCHAR2(25) NOT NULL,
GENDER CHAR(1) NOT NULL,
BIRTHDATE DATE NOT NULL,
HIREDATE DATE NOT NULL,
SALARY NUMBER(15,5) NOT NULL,
DEPTNO NUMBER(15,5) NOT NULL
CREATE UNIQUE INDEX DEPT_PK ON (DEPTNO);
After inserting one million rows into the EMP table, the table consumes 72 MB and the primary key index consumes 16 MB. That’s about 22% overhead just for the primary key index. However, there’s nothing we can do about that since the primary key enforces a business requirement. Now let’s see which departments have employees who make more than the department average. Here’s the SQL.
select dept.deptno, count(*)
from dept join emp on dept.deptno = emp.deptno
where salary > (select avg(salary)
from emp
where emp.deptno = dept.deptno)
group by dept.deptno
order by dept.deptno;
This SQL statement took 265 milliseconds to execute. The first thing that one might logically test is indexing the employee foreign key column (EMP.DEPTNO) since there is a join to the department table. That adds another 16 MB bringing the total index overhead to 44% for zero improvements in execution time. Moreover, the execution plan steps and costs are identical as shown in Figure 2. So this initial indexing attempt yields “foe” (i.e. more space for no gain).
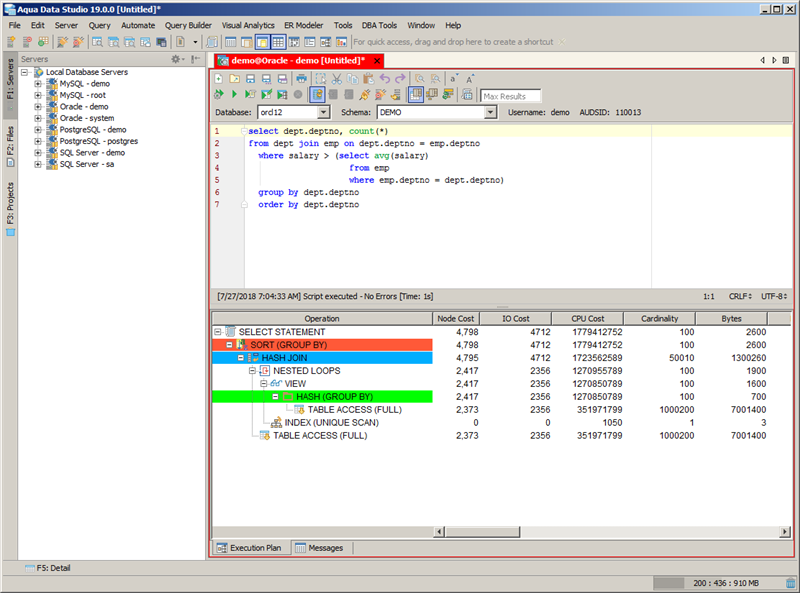
Figure 2: SQL Execution Plan for First Index
To improve this SQL statement requires an index which contains all the columns actually referenced by the query. So the second index attempt is as follows:
CREATE UNIQUE INDEX EMP_PK ON (DEPTNO, EMPNO, SALARY);
This SQL statement now only takes 218 milliseconds to execute, thus representing an 18% reduction. More importantly, this new execution plan shown in Figure 3 reduces the IO cost by 66%! Since IO is generally accepted as the “Achilles’ Heel” of any database, this IO reduction is extremely significant. However, this index consumes an additional 24 MB of space bringing the total overhead to 57%! So the question becomes how would you rate this scenario: “friend” or “foe”?
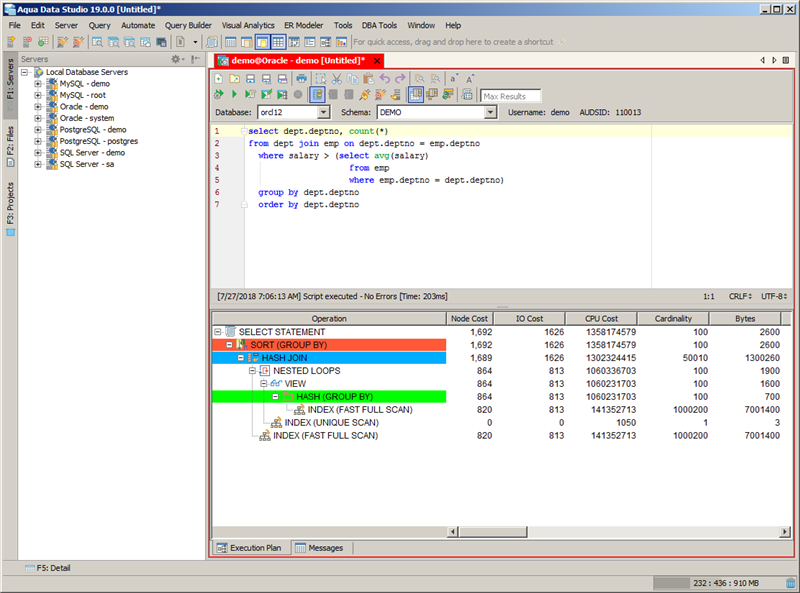
Figure 3: Possible Ideal Execution Plan
Referring back to Brent Ozar’s blog, he states that “Index tuning is a lot like losing weight: The longer you wait to do it, the harder it is.” I agree. Plus with the relative overheads that any index adds it could well be that while an index diet is advisable, that actual index weight loss might be extremely difficult to achieve. Because as was demonstrated in this blog, sometimes you have to give a little to get a little. While these demo tables and indexes probably are somewhat artificial in nature, the basic conclusions should nonetheless hold true. You need to consider all ramifications of adding new indexes. You must consider not just the improvements they might offer, but the space they consume. Your tables may be far wider and thus the overhead percentages much lower. But the pattern remains, it takes space to get performance improvements. Therefore you should be careful when adding indexes to be sure that the gains justify the costs. Don’t just add indexes under the assumption that all indexes are automatically our “friends”.