Collaborative Holistic Tuning of the Application Stack
When planning for this blog, I deliberated over the title much more than anyone should ever deliberate over anything. But I knew the subject I wanted to cover and it spanned a number of ideas. But a descriptive name was too long and a pithy name seemed too vague. The votes were heavily in favor of the pithy name but descriptive had some advocates (including me.) So I named it twice, like Dr. Strangelove or: How I Learned to Stop Worrying and Love the Bomb.
Trivia Question: What is the next to last line in Dr. Strangelove? (Answer at the end and it relates to the subject. No fair using Google to cheat.)

Why User-Centric?
Every application, every delivery system, every piece of intermediate hardware or software is ultimately going to be judged by how well it meets the needs of the end users. You wouldn’t think this revelation should surprise anyone, but you might be surprised at how many times individual components are tuned or optimized with the assumption that the sum of optimized components yields an optimized whole.
It is just easier for teams to only worry about components they control and make sure they have a firm case that any problem must clearly be outside of their area. But that approach rarely works, because unhappy users blame everybody associated without respect to relative guilt. When business is impacted, the consequences also frequently are felt by all as well.
Why Collaborative and Holistic?
All elements of the application stack are inextricably related to each other in how well they serve the end-users together. And since optimum design for each component considered independently can be counter-productive at worst and sub-optimal at best; a holistic approach to all related components of the application stack is necessary.
Since different components of the application stack are usually controlled and managed by different teams or even organizations, a collaborative approach is necessary to achieve optimization of the whole.
Reactive versus Proactive
These words are used so much in system management that they have almost become meaningless. Proactive is good and Reactive is bad; so we all need to be more proactive. But being efficient when we are required to be reactive is also critical as all contingencies cannot be eliminated.
Reactive tasks are more individual and require efficient diagnosis of problem, isolation to a root cause component, and quick correction of that root cause issue. We frequently refer to being prepared with systems that increase the efficiency and accuracy of this deductive process as being proactive in itself. Detecting problems before users are impacted and fixing them is being proactive from the end users’ perspectives.
But our subject here is tuning of the application stack as a whole and that clearly requires a proactive approach. Proactive is methodical and consistent
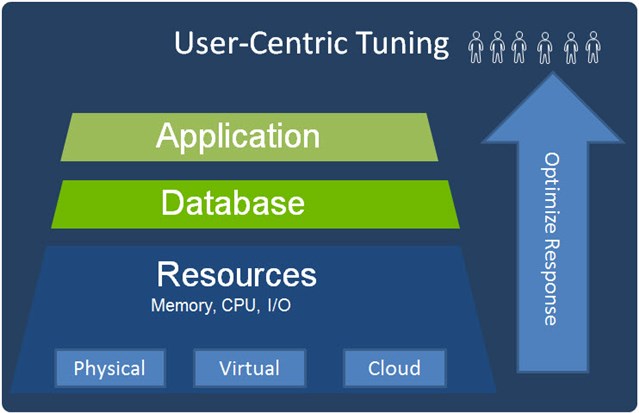
The Application Stack
For this discussion, we are considering specifically database applications with structured query language interfaces from the applications to the database. Users interact directly with applications which deliver some service or benefit to them. The applications and databases both run on resources that may be in physical datacenters, virtual environments within such datacenters, or residing in cloud resources that may be hosted in variable environments. But in all cases they will be consuming physical resources “somewhere” of memory, CPU, and I/O bandwidth.
The teams responsible for these different layers of the application stack vary by organization. Often databases and applications are handled by different teams if not completely different companies. And the resources hosting the application or the database portions may also differ in hybrid cloud environments, with portions hosted locally and other portions in the cloud, or hosted in different cloud environments or partially virtual environments.
Interdependency
As referenced earlier, the interdependency of the application stack means optimization of components in isolation will never lead to optimal overall performance. Tuning and optimizing a database for poor performing application will necessarily be incorrectly configured when those application issues are resolved. And how can anyone possibly size the environments for these changing, but inefficient applications and databases?
Blamestorming
Here is where most performance management and tuning products have long made the same claims to “eliminate the blame game”, but the real effect at best was to optimize the blame game. The objectives are to identify root causes of problems and also provide evidence when your particular component should be held blameless.

While winning the blame game may be better than losing the blame game, the ideal solution for all would to be to truly collaborate in tuning efforts so that all have some confidence. If all teams can work together in a unified front, then all can be reasonably certain the resulting performance is the best that can be achieved.
A Few Performance Myths
Before we talk about any optimization and tuning approach, I want to debunk a few myths I have heard repeated often to rationalize not worrying about performance tuning.
- “Memory is cheap”
- “Storage is cheap”
- “Processing power is cheap”
These are usually spouted when someone just wants to throw brute power at an application performance problem. Why waste effort optimizing resource usage when resources are not a problem?
Relatively speaking to past prices, all these statements may be true. But anyone who has had to defend a capital or operations budget knows that getting funding is a different matter. And as resources have gotten cheaper, complexity of applications has increased so that we still have the same optimization issues.
In fact, the mantra of information technology for the past few decades has been “Do more with less” rather than exploiting ‘cheap’ resources with overpowered environments.
Tuning is needed.
Optimize by Layers
Beyond encouraging collaboration across teams, the unifying theme of this approach is to optimize by layers through the application stack.
The rationale behind this approach is to optimize one layer at a time, but in an order that insures optimization of other layers will not undo whatever gains you have achieved.
The disconnected approach of optimizing by component independently can easily lead to an unpleasant game of IT whack-a-mole.

Database teams optimize performance against a poorly designed application with poorly tuned SQL statements. Then the physical resources are inadequate. Then the application is improved in a way that overwhelms the database tuned to the previous poor performing application.
As in any other diagnostic scenario, you want to change one thing at a time so that you know which changes lead to improvement.
Application SQL Comes First
SQL from the application represents the workload on the database. So, before making any database or resource environment changes it necessarily must be optimized first.
SQL from the application will be limited by resource availability in the database itself. The logical I/O of the SQL workload may be artificially reduced by contention within the database from resource waits or queuing. And that may make the resource utilization look more favorable than it should be.
So we can’t really use response time or physical I/O performance of the SQL for optimization purposes.
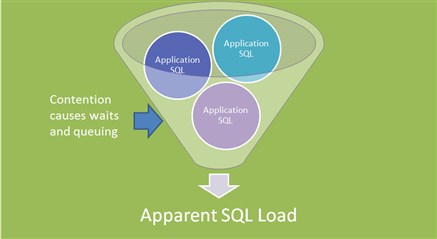
Application logic and system design can certainly help user performance, but our main goal here is to optimize the logical I/O measure, logical reads and writes, before attempting other changes.
Total workload is the concern here, so worst performing SQL is not necessarily the best place the start. Frequently executed SQL improvements can yield a greater total improvement than an infrequently called “worst SQL” statement.
Tune the Database Instance to the Optimum SQL Workload
Now, we can tune the database instance in confidence to meet the optimized logical load of the application. Setting memory allocations, indexes, and storage distribution to increase performance now makes sense. It is important not to rely on database self-optimization features. While these automated capabilities can be very useful, in some cases auto-optimization can cause problems and may need to be overridden depending on the application and SQL.
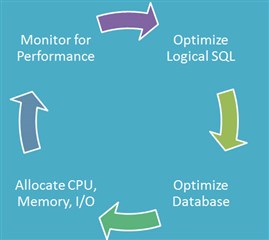
Allocate Resources
Only after the application and database layers of the application stack have been optimized should you determine the resource requirements for the desired performance for the end users. The optimization efforts will ensure that no money is being wasted in hardware procurement or cloud usage fees. And the proper processor, memory, and storage requirements for the application can be determined for the desired application performance and projected user load for the organization in question.
Monitor and Repeat
The final phase of this user-centric database application tuning approach is the same as it has been for most DBA tasks. Monitor and repeat. Application loads change and sometimes increase dramatically with company changes. Technology changes and new and more efficient resources may come online that change the approach used for a particular application.
Continuous monitoring is needed, not just to catch anomaly situations, but to detect performance change trends. But the methodical tuning of each layer must be maintained as it is repeated.
The Right Tools for the Right Jobs
Depending on your organization structure, one team or even one person may be doing all the tuning tasks through the application stack. However, in most cases this work will be distributed across multiple teams.
While a single, multi-purpose tool might be used to help with all these tasks; it would certainly be overkill for certain development teams, for example.
Tools specific to tasks and teams means Developers and DBAs can focus on their tasks within this collaboration with user interfaces and capabilities appropriate for those tasks.

Trivia Answer: “Sir, I have a plan!”
Then the world blows up.
Don’t wait until your world is blowing up to implement your plan to optimize your application performance.