
This month’s #tsql2sday is hosted by the delightful Jes Borland over at Less Than Dot, on the topic of XEvents. When I saw this come up on Twitter I was unsurprised to see the usual chatter about how folks know that they should be using XEvents these days, but they’re used to SQL Profiler and so they turn to it in a pinch. When I mentioned that I’ve been using Idera’s free tool for this purpose it seemed that not a lot of folks had heard about it, so I thought I’d give a brief introduction to the tool.
In design, SQL XEvent Profiler is intended to make it as quick and easy to get XEvent sessions up and running as it always was with SQL Server Profiler – to wit, using the same familiar sequence of clicks:
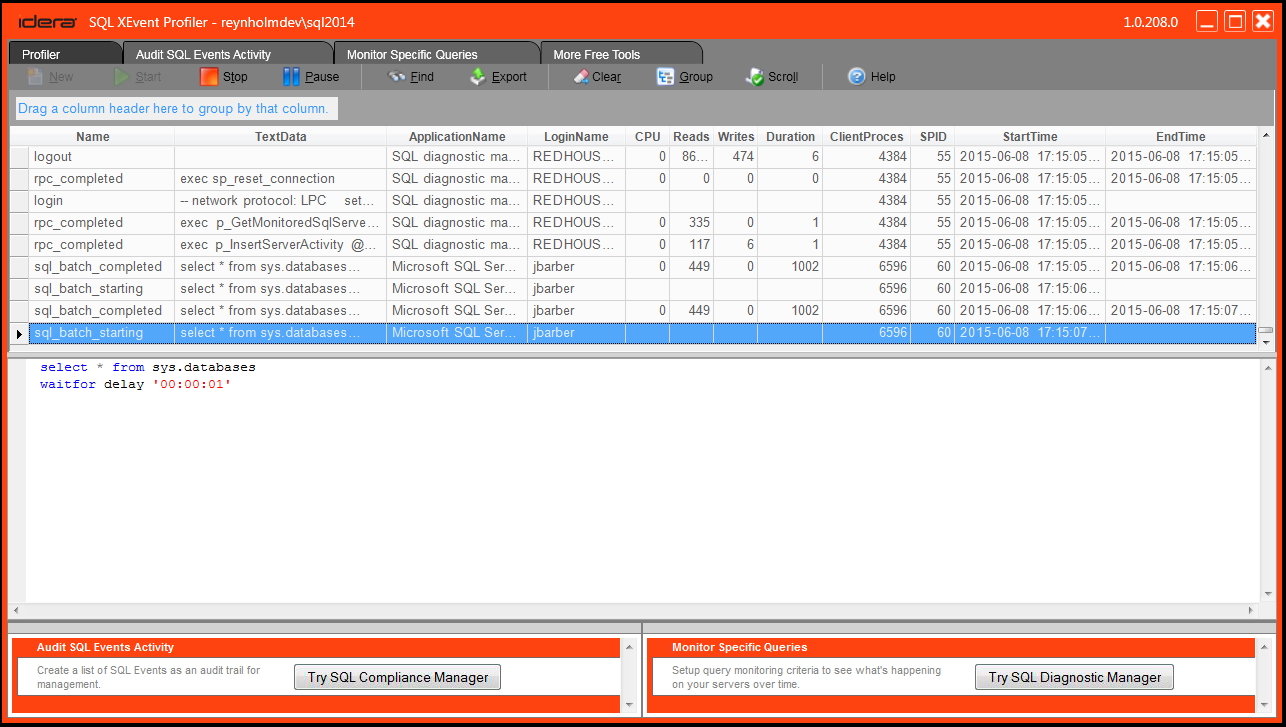

Now, you do have a few more options – you can change templates, add filters, etc – but there’s not much more to it than that! This tool is intended for very quick little troubleshooting sessions. For more complex sessions you may want to use the native tool in SSMS or write your own session, but if you’re like me and occasionally just want to just take a look at what’s running without much fuss, the XEvent Profiler tool may be worth a shot.
Last summer I blogged about my favorite feature of XEvent Profiler – column grouping! Hop over here to give it a read.
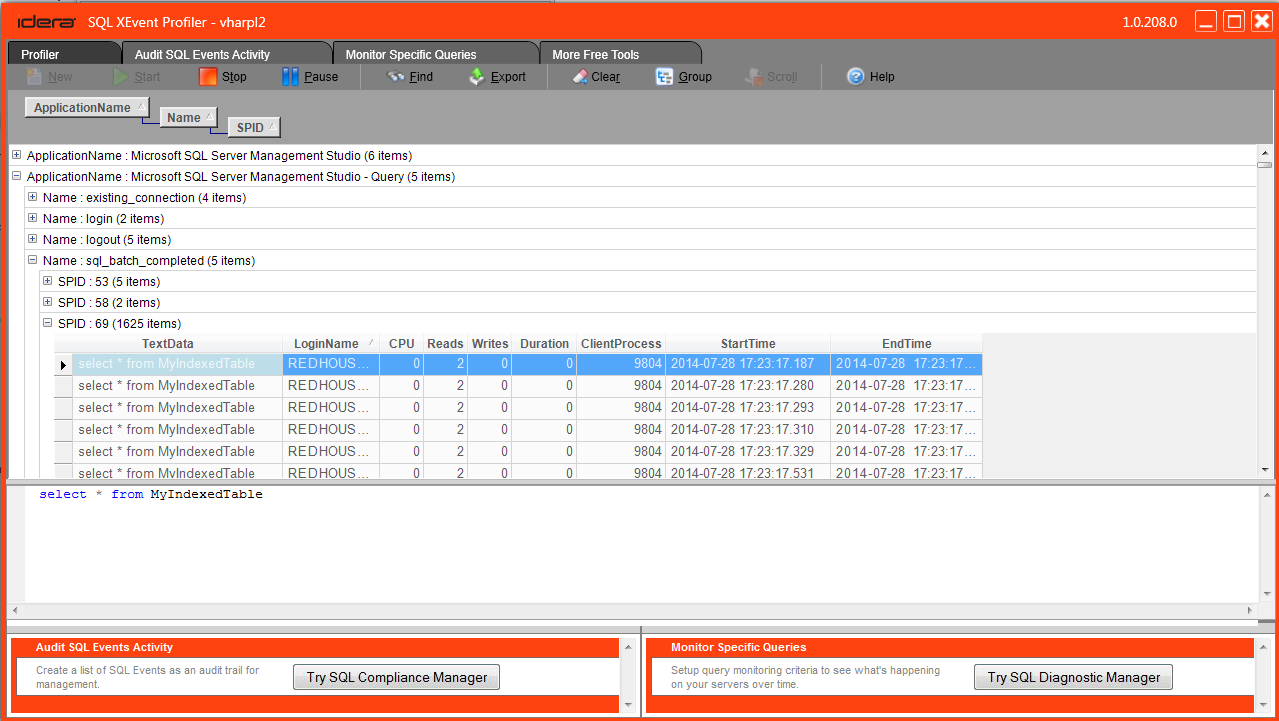
As a bit of background – one of the interesting things about this tool is that it is built using the Microsoft.SqlServer.XEvent.Linq assembly, which means that sessions created by it are read using the .Net XeReader as described here. In our internal testing we’ve found this is a much more lightweight way to read events than doing the sometimes heavy XML shredding of other methods, and thus it is well suited to a point and shoot tool like this.
You can download XEvent Profiler for free from the main Idera website, and you can let us know how it works for you and give us feature requests here in the forums. And as always, you can look me up here or on Twitter and let me know what you think.
Thanks again to Jes for hosting this month’s T-SQL Tuesday, and be sure to hop over to the host page to learn more about XEvents from bloggers all around the world!